
Pythonを使ってWebサイトから情報を取得する方法はいくつかありますが、その中でも最もポピュラーなのがRequestsライブラリを使ったものです。
今回はRequestsライブラリの基本的な使い方について学んでいきたいと思います。
なお、今回の記事では以下の書籍を参考にさせていただいています。
【Amazon】Pythonクローリング&スクレイピング[増補改訂版] -データ収集・解析のための実践開発ガイド
Requestsについて
Requestsは、Python用のサードパーティー製ライブラリです。
WebサイトからWebページを取得するのによく使われます。
Python標準モジュールにurllibというものもあるのですが、使い勝手があまりよくないのでRequestsを使う方が多いようです。
Requestsではurllibでは扱うことが難しかったヘッダ追加やBasic認証についても簡単に扱えるようになっています。
Requestsの基本的な使い方
以前「Anaconda仮想環境にスクレイピング用ライブラリを導入」の中でRequestsはインストール済みですので、インポートすればそのまま使えます。
![]()
Requestsを使ってのWebページ取得には、get()関数を利用します。
引数として取得したいWebページのURLを指定します。
![]()
get()関数により取得できるのはResponse型のオブジェクトです。
Responseオブジェクトには様々な属性が定義されており、各属性を参照することにより必要な情報を取得します。
例えば、BODYに格納されたコンテンツをデコードされた状態で取得する場合にはtext属性を参照します。
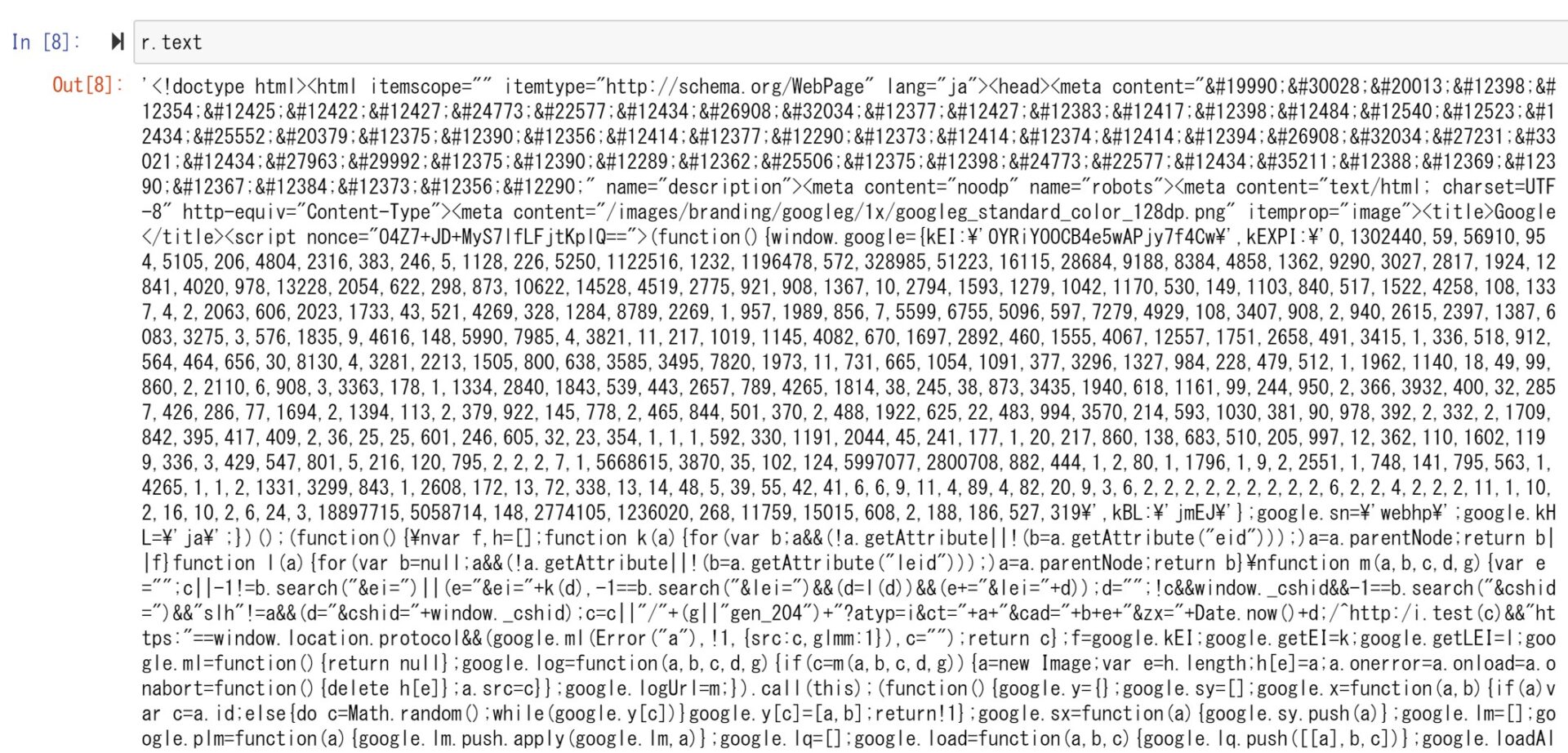
Responseオブジェクトのよく使う属性を以下にまとめます。
| 属性 | 内容 |
| status_code | HTTPのステータスコードを返す |
| encoding | レスポンスのエンコード方式を返す。 書き換えるとtext属性取得時のデコード方式を変更できる。 |
| headers | ヘッダーを辞書形式で返す |
| text | レスポンスのBODYをencodingでデコードして返す |
| content | レスポンスのBODYをbyte型で返す |
Requestsの高度な使い方
JSONパーサー
最近はAPIで情報を提供しているサービスがたくさんあります。
APIで取得できる方法はJSON形式で返されることが多いです。
Requestsのget()関数で取得できるResponseオブジェクトには、JSON形式のテキストのパーサであるjson()メソッドがあります。
json()メソッドはJSON形式を解析して、プログラムで扱いやすいdictやlist形式で戻してくれます。
json()メソッドを使ってみる
天気予報APIというサイトでは、各地域の天気情報をJSON形式で返してくれるAPIを公開しています。
[外部サイト]天気予報API使い方は簡単で、基本URLと地域コードを合わせたURLに対してGETリクエストを送信するだけです。
例えば、東京地域に関する天気情報を取得してみます。
基本URLである「https://weather.tsukumijima.net/api/forecast/city/」に、東京の地域ID「130010」を組み合わせてRequestsからGETリクエストを送ります。
上記のようにResponseのBODYにはJSON形式で天気情報が格納されていることがわかります。
これをjson()メソッドで解析してみます。
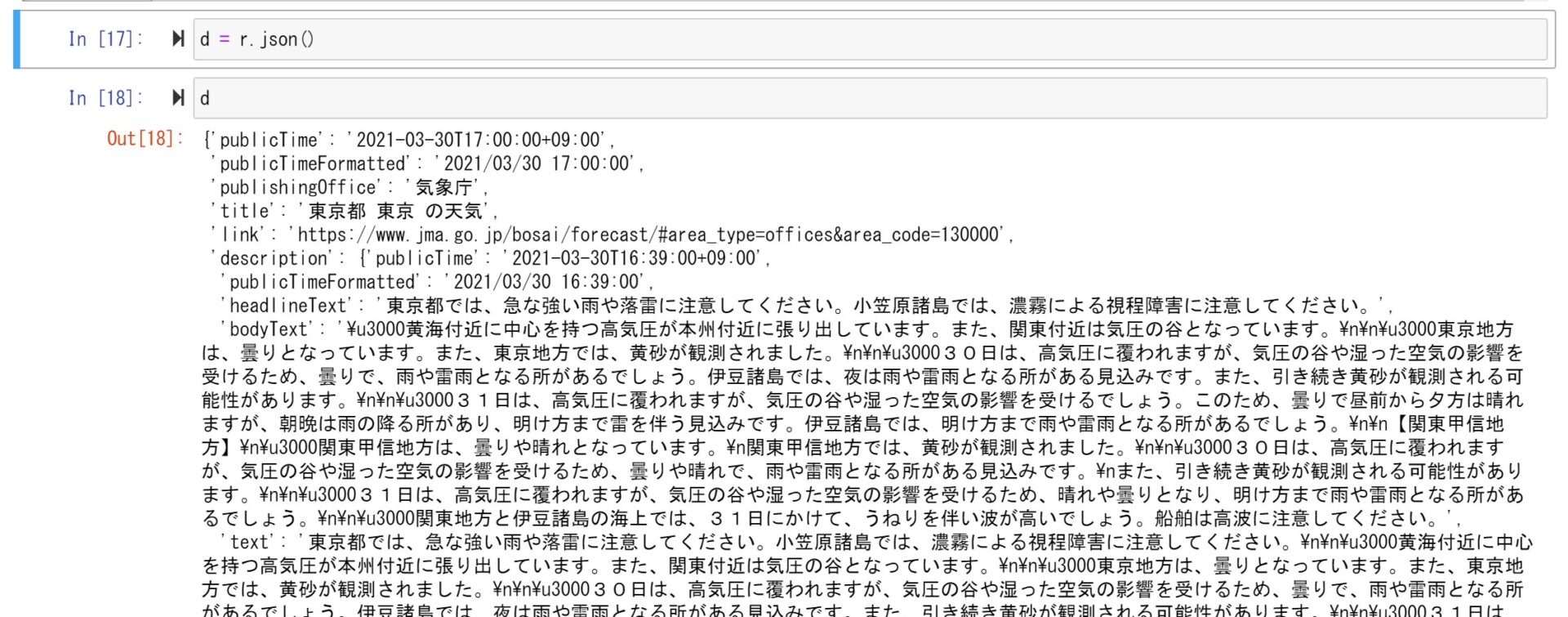
JSON形式のテキストが成形されて、dict形式のデータが取得できました。
ここから明日の最低気温のデータを摂氏で取得してみます。
取得したdictの構造を見ると、forecastsの下に今日、明日、明後日の順にlist形式でデータが保存されているようです。
明日は2番目なので、1を指定します。
気温の情報はtemperature の下にあり、minが最低気温を示しているようです。

よって、気温データにアクセスするには、次のようになります。
d["forecasts"][1]["temperature"]["min"]["celsius"]
上手く取れました。明日(2021年3月31日)、東京地方の最低気温は摂氏14度のようです。
このように、JSON形式の情報を辞書形式に変換することによって、必要な情報に簡単にアクセスすることができるようになります。
Keep-Alive
Requestsのget()関数は、実行するたびに対象サイトとのTCPコネクションを確立しに行きます。
同一サイト内で複数ページを取得する場合、get()関数を繰り返すとTCPコネクション確立時のオーバーヘッドが大きくなります。
TCPコネクション確立時には3Wayハンドシェイクという手続きが必要であり、複数回のやり取りが必要です。
特にHTTPS接続時にはTLS/SSLハンドシェイクという手続きが行われ、こちらはサーバーへの負荷が大きめの処理となります。
このため、同一サイトと複数回通信を行う場合、最初に確立したセッションを維持したまま複数ページを取得するKeep-Aliveという接続方法が用いられます。
Keep-Aliveを使ってみる
Keep-Aliveを利用するには、事前にSessionオブジェクトを作成しておく必要があります。
RequestsはKeep-Alive方式に対応しており、Keep-Aliveを使用するためにはSession()関数を用います。
Session()関数を呼び出すとSessionオブジェクトが返されます。
あとはSessionオブジェクトのget()メソッドを呼び出せばKeep-Aliveを利用することができます。

パット見わかりませんが、同じセッションを用いて二つのページを取得できています。
まとめ
今回は「Python使ったWebページ取得 Requestsの基本的な使い方」という内容でお伝えしました。
この記事が皆さんのお役に立てば幸いです。


